
vLLM
Kurulum & Uyumluluk
| Lisans | ⚖️ Apache-2.0 — açık kaynak, kullanımı ücretsiz |
|---|---|
| cPanel ile kolay kurulur mu? | Hayır — sunucu gerekir |
| Sunucu ihtiyacı | VPS/sunucu; GPU önerilir |
| Veritabanı | Gerekmez |
| Yerelde (local) çalışır mı? | Evet |
| Barındırma şekli | Sunucuda host gerekir |
Kısaca nasıl kullanılır?
* Bu kurulum/uyumluluk değerlendirmesi, yazılımın teknik yapısına göre e-veri.com tarafından yorumlanmıştır.
Ekran Görüntüleri
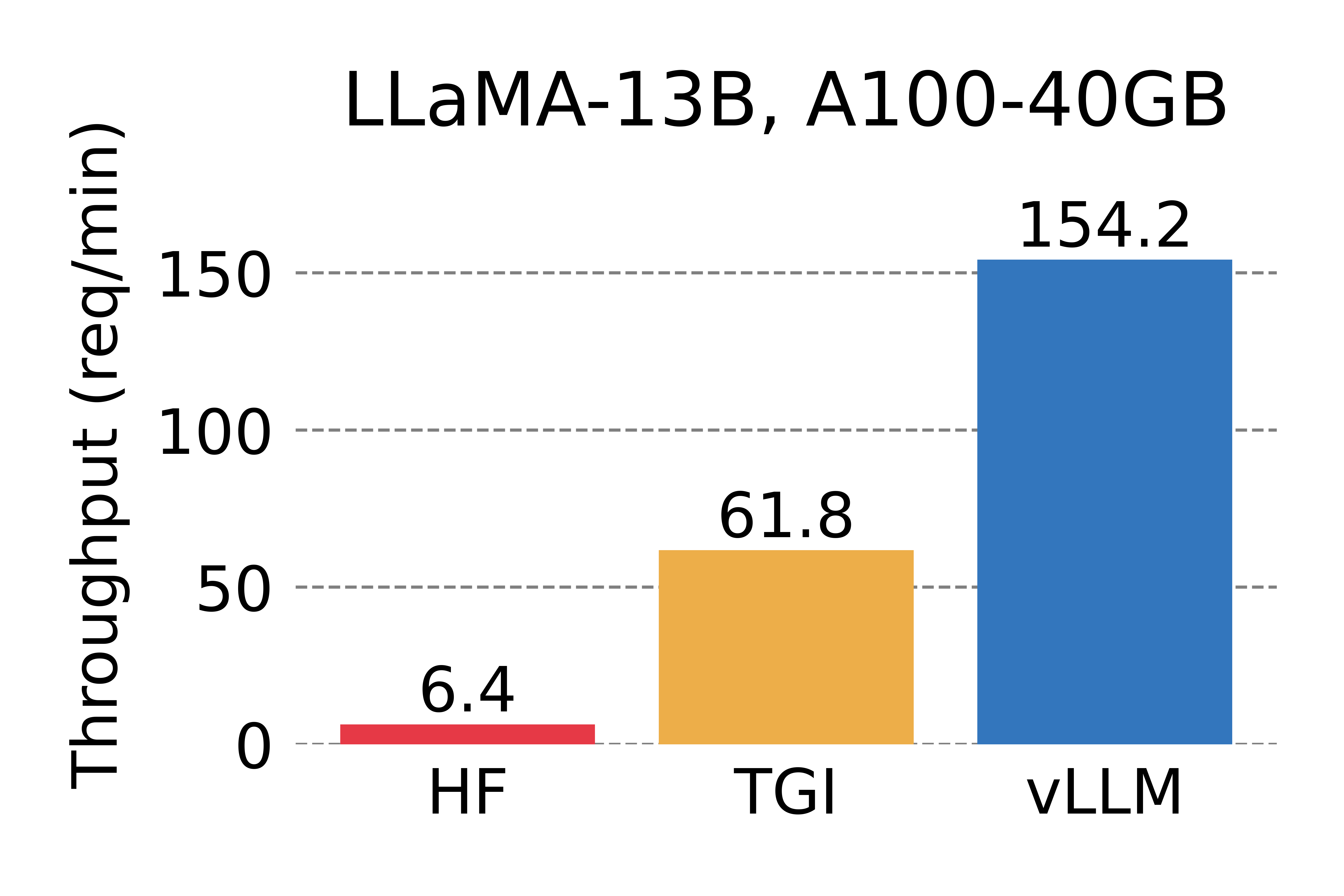
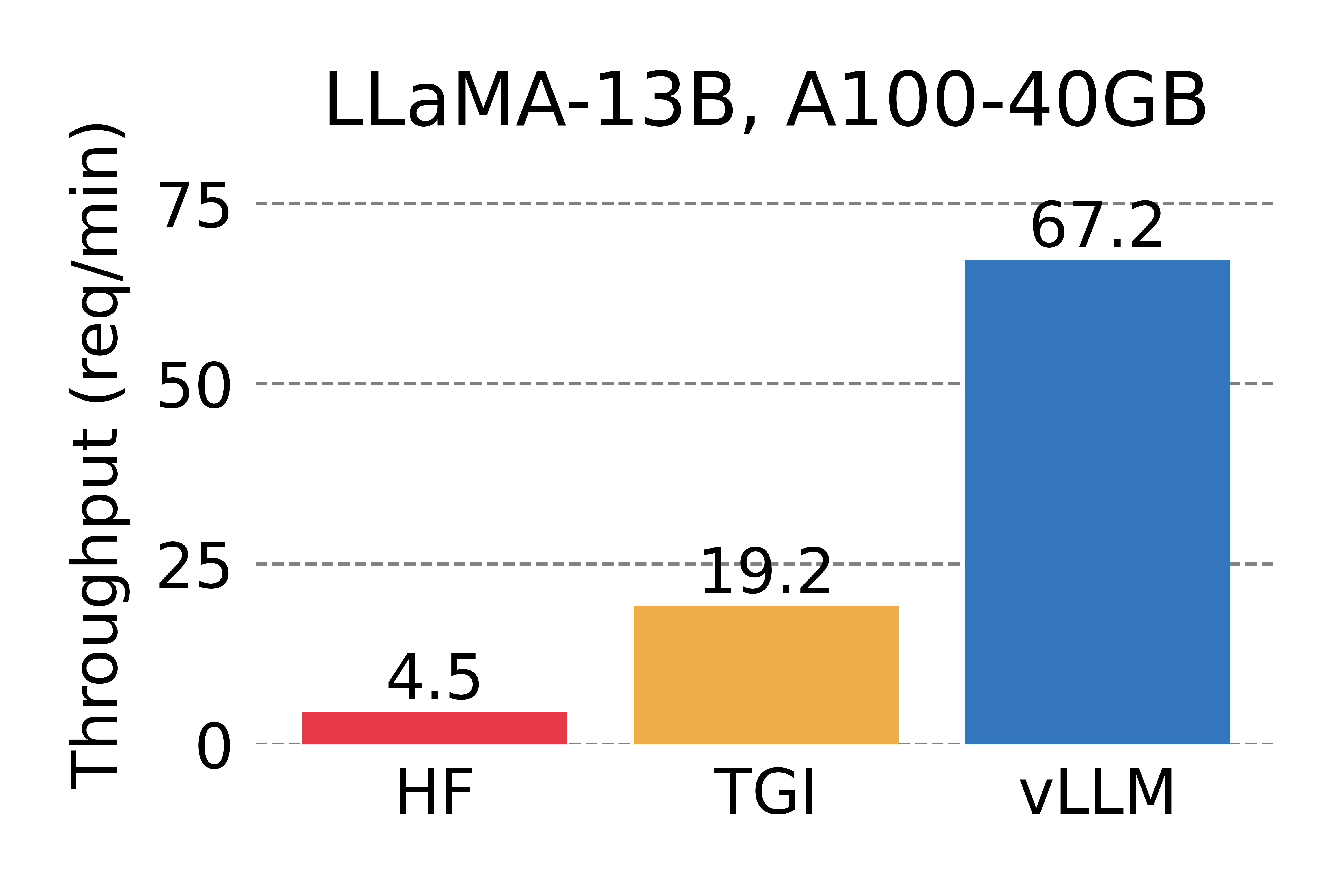
Bu yazılım ne işe yarar?
vLLM, büyük dil modellerini (LLM) üretim ortamında hızlı, bellek-verimli ve düşük maliyetle servis etmek için tasarlanmış açık kaynak bir çıkarım (inference) ve sunum motorudur. Berkeley Sky Computing Lab'da geliştirilen proje, bugün 2000'i aşkın katkıcının desteklediği yapay zeka altyapısının fiili standartlarından biri haline gelmiştir.
Neden vLLM?
vLLM'in temelinde, GPU belleğini işletim sistemlerindeki sayfalı bellek mantığıyla yöneten PagedAttention teknolojisi yer alır. Bu sayede dikkat (attention) önbelleği israf edilmeden kullanılır ve aynı donanımdan kat kat daha fazla eşzamanlı istek karşılanır. Sürekli batch (continuous batching), önek önbellekleme ve parçalı prefill gibi tekniklerle gelen istekler dinamik olarak gruplanarak GPU sürekli meşgul tutulur; sonuç, geleneksel çözümlere kıyasla belirgin biçimde yüksek verim ve düşük gecikmedir.
Üretime hazır uyumluluk
vLLM, OpenAI uyumlu bir API sunucusu sunar; mevcut OpenAI istemcilerinizi yalnızca uç noktayı değiştirerek kendi altyapınıza yönlendirebilirsiniz. Hugging Face üzerindeki 200'den fazla model mimarisini doğrudan destekler, FP8/INT4/GPTQ/AWQ/GGUF gibi nicemleme (quantization) formatlarıyla maliyeti düşürür ve tensor, pipeline, veri ile uzman paralelliği sayesinde tek GPU'dan çok düğümlü kümelere kadar ölçeklenir.
- PagedAttention ile yüksek bellek verimliliği
- Sürekli batch ve önek önbellekleme ile yüksek istek hacmi
- OpenAI uyumlu REST API ve çoklu LoRA desteği
- NVIDIA, AMD, CPU, TPU ve özel hızlandırıcılar için geniş donanım uyumu
Öne Çıkan Özellikler
Kurumsal Kullanım Senaryoları
- Kendi LLM API'niz: OpenAI uyumlu uç noktayı kendi sunucularınızda çalıştırarak harici sağlayıcıya bağımlı kalmadan ekiplerinize ve uygulamalarınıza dahili bir yapay zeka API'si sunun.
- Maliyet ve gizlilik kontrolü: Token başına dış servis ücreti ödemeden, hassas kurumsal verilerinizi kendi altyapınızdan dışarı çıkarmadan modelleri çalıştırın; KVKK ve veri ikametgahı gereksinimlerini karşılayın.
- Yüksek trafikli yapay zeka servisleri: Sohbet botları, RAG tabanlı arama, müşteri destek asistanları ve içerik üretim hizmetlerinde binlerce eşzamanlı isteği tek bir GPU kümesiyle karşılayın.
- Çoklu model ve LoRA dağıtımı: Farklı departmanlar için ince ayarlı LoRA adaptörlerini tek bir servis üzerinde yöneterek donanım kullanımını en üst düzeye çıkarın.
- Toplu çıkarım iş yükleri: Doküman özetleme, sınıflandırma ve gömü (embedding) üretimi gibi yüksek hacimli batch görevlerini ekonomik biçimde işleyin.
Kimler için: vLLM; kendi yapay zeka altyapısını kuran kurumlar, MLOps ve platform mühendisliği ekipleri, açık kaynak LLM'leri üretime taşımak isteyen yazılım firmaları ve veri gizliliği ile maliyet kontrolünü öncelik haline getiren kuruluşlar için uygundur. Dış API maliyetlerini düşürmek, verilerini kendi sunucularında tutmak ve yüksek trafikli yapay zeka servislerini ölçeklendirmek isteyen teknik ekipler için idealdir.
vLLM için e-veri.com hizmetleri
Açık kaynak yazılım ücretsizdir; e-veri.com kurulumunu, yönetilen hosting'ini ve sürekli desteğini kurumsal güvenceyle üstlenir. Aşağıdan size uygun paket için ücretsiz teklif alın.
Kurumsal Kurulum
- Sunucu hazırlığı ve güvenlik
- Kurulum + Türkçe yapılandırma
- Veri/ürün aktarımı
- Eğitim oturumu
Yönetilen Hosting
- Önceden kurulu ortam
- Otomatik yedek
- Güncelleme & izleme
- SSL dahil
Destek & Bakım
- Öncelikli destek
- Düzenli güncelleme
- Yedek doğrulama
- Aylık sağlık raporu